
本文由林清猫耳投稿
原文:https://www.jianshu.com/p/b2e077c07c70
全文2277字 | 阅读需要12分

前言
Instagram上有很多非常好看的照片,而且照片类型非常全,照片质量也很高。但是有个问题,不管是在移动端还是在网页端都不能通过长按或者右键方式进行图片保存。
看了下知乎问题 “怎么下载保存 Instagram 上喜欢的图片到手机?” 下的回答,基本都要复制图片链接到其它软件或者微信公众号之类的来获取源图片。于是我就想能不能写一个爬虫,传入一个喜欢的博主账号名称然后爬取该博主所有的照片和视频。
下面是折腾一天后的成果:
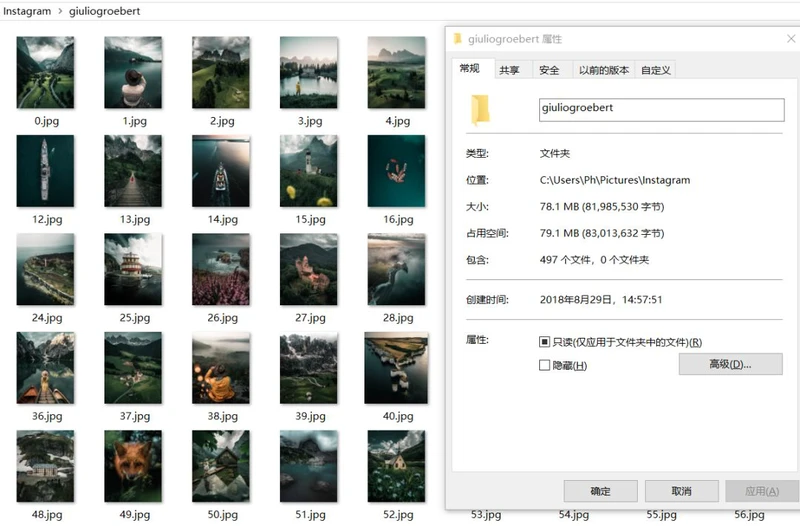
所需工具和整个爬虫结构
requestsrejsonpyqueryjavascript
获取网页源代码
首先要确保自己对 https://www.instagram.com 发起的请求能返回正常的响应内容。正常的响应内容包括HTML,Json字符串,二进制数据(如图片类型)等类型的内容。
headersuser-agentcookieproxies
以下是获取的网页源代码:
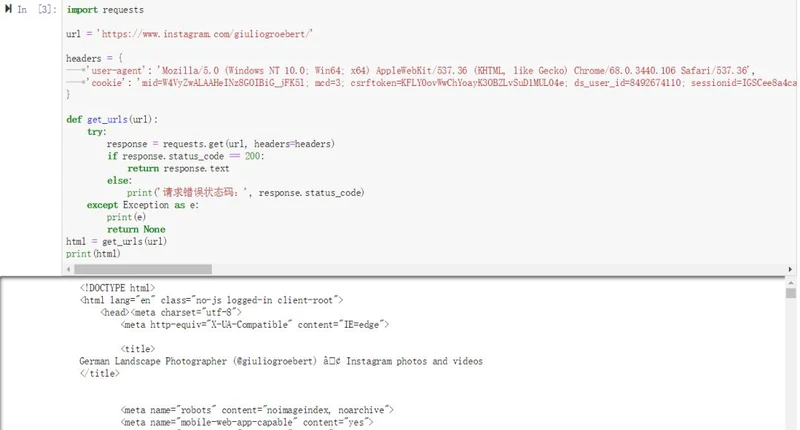
分析页面
indexHTML
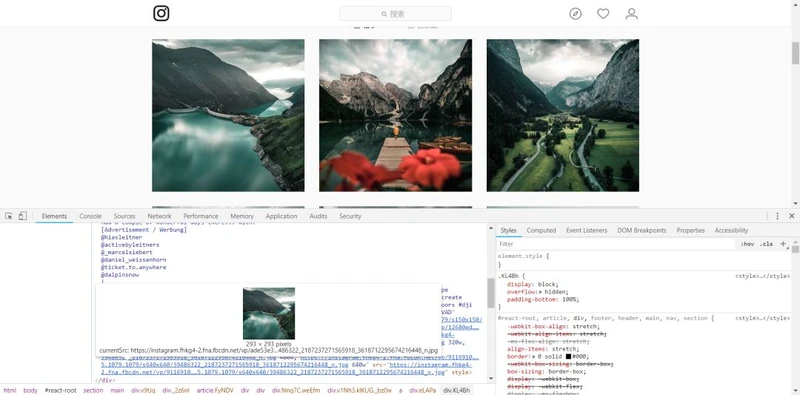
缩略图
divv1Nh3 kIKUG _bz0w
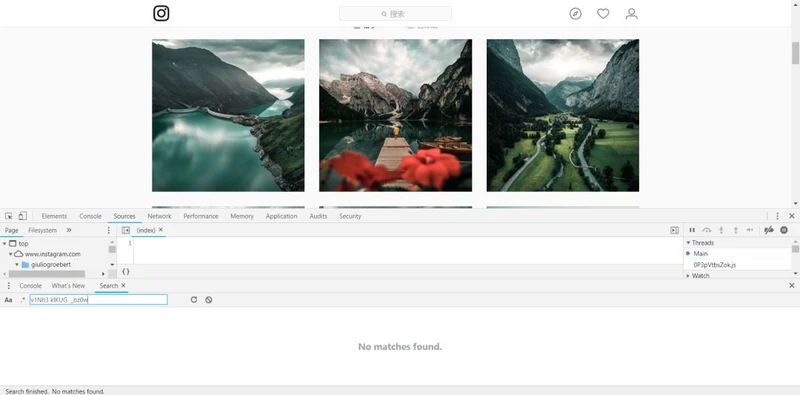
Source
CtrlUCtrlF

Find URL
scriptwindows._shareData
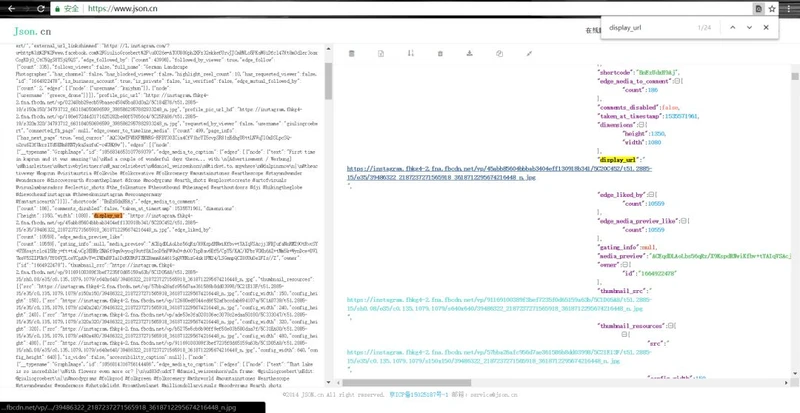
json数据块
display_url nodes
获取的urls如下:
到这里确实已经拿到了该Ins博主的照片url,但是这里只有12条,那么其它的照片url在哪里呢?
分析XHR
AjaxXHR
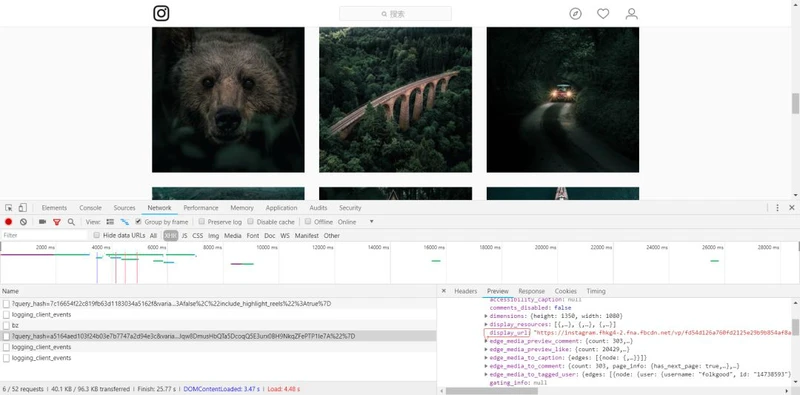
XHR
XHRJson
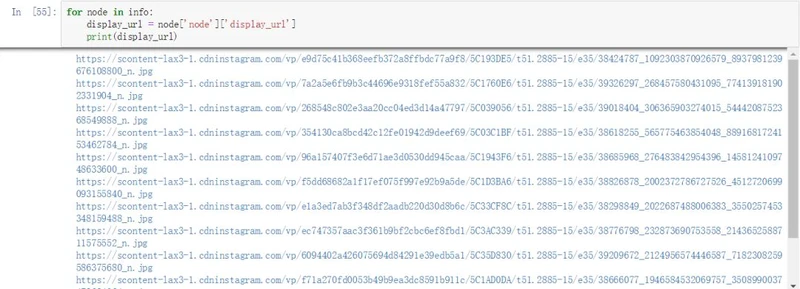
urls
这里新的问题出现了,一条XHR请求还是只有12张图片啊,这位博主一共有近500条帖子,仅为了12张图片就要去看XHR请求复制url一次也太反人类了。于是开始分析XHR请求的url。
分析XHR请求的URL
下面是其中一条XHR请求的url:
https://www.instagram.com/graphql/query/?query_hash=a5164aed103f24b03e7b7747a2d94e3c&variables=%7B%22id%22%3A%221664922478%22%2C%22first%22%3A12%2C%22after%22%3A%22AQBJ8AGqCb5c9rO-dl2Z8ojZW12jrFbYZHxJKC1hP-nJKLtedNJ6VHzKAZtAd0oeUfgJqw8DmusHbQTa5DcoqQ5E3urx0BH9NkqZFePTP1Ie7A%22%7D
其中的参数有:
ididfirst
我心想这下问题该解决了吧,只要把first改成图片总数-12不就可以爬取所有图片了。
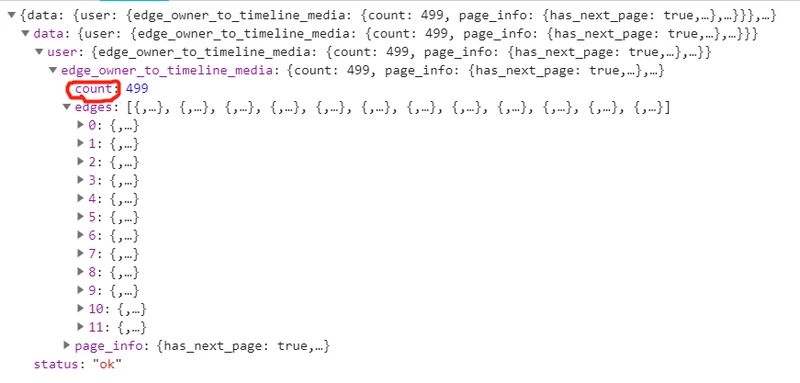
count
countcountfirstcount-12
第一次下载只有62张图片,于是新建一个文件夹重新下载,还是只有62张图片。其中前12张是从HTML文件总取得的,那么后面这50张图片应该就是该XHR请求返回的urls。这下我意识到,一次XHR请求返回的Json字符串最多只能容纳50条图片url,所以这个办法是行不通的。
afterafter
XHRJson
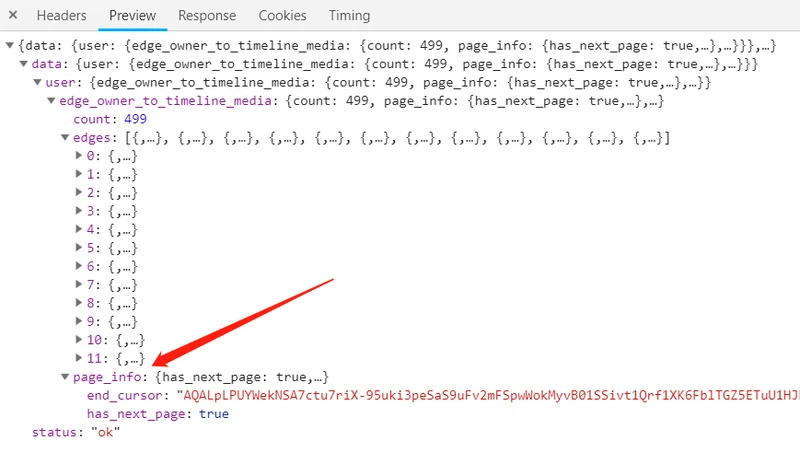
page_info
end_cursorhas_next_page
afterquery_hashidfirstidfirstend_cursorafterhas_next_page
也就是说这些看似一团乱码的XHR请求的url其实都是有序的,从包含第13-24张帖子内容的url开始,按博主发帖子的时间顺序构成XHR请求的url序列,每条url的响应内容包含12条图片或视频链接。
whilehas_next_pageFalseend_cursorhas_next_page
一些小问题
爬虫到了这里其实已经完成的差不多了,但还是有一些小问题。
问题1:初始游标
现在可以通过XHR请求的响应内容提取下一条XHR请求的url参数值以进行全部图片的url提取。但是每一条XHR请求的url包含的都是下一条XHR请求的url参数值,那么第一条XHR请求的url参数怎么确定?
F12NetworkXHRaftercursor

cursor
end_cursorafter
问题2:博主id
用中学数学常说一个词:同理可得。 嗯同理可得,博主id在一开始的HTML文件中也一定用,直接用正则匹配一下就有了然后传入每一条XHR请求的url中即可真正实现解放双手。
贴上问题1和问题2部分代码:
第64行和第56行
问题3:视频
到这一步已经实现只传入博主账号名称提取该博主所有图片url的骚操作了。但经过几个博主的爬取实测,发现原本的视频爬下来只是图片,于是继续分析XHR请求的响应内容Json字符串内容。
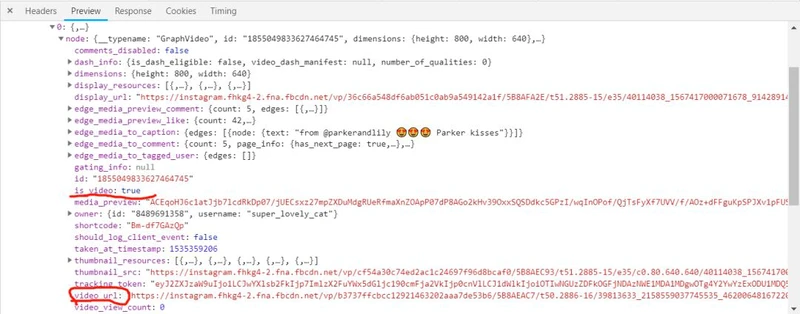
video
nodeis_videovideo_url
85行 - 89行
爬取效果
爬取效果如图:
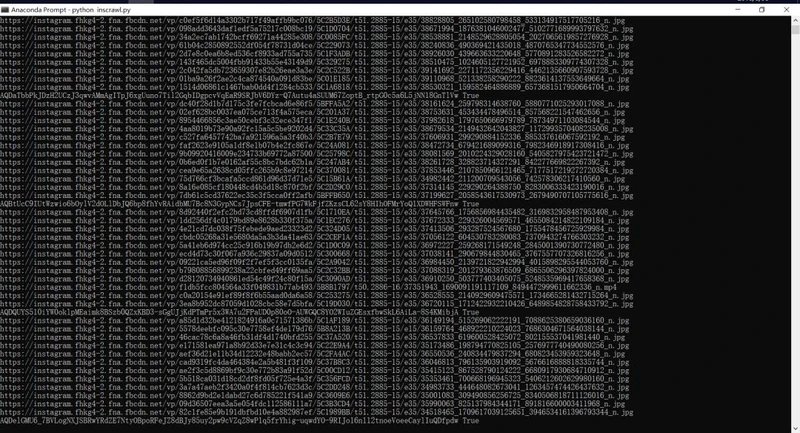
get_urls
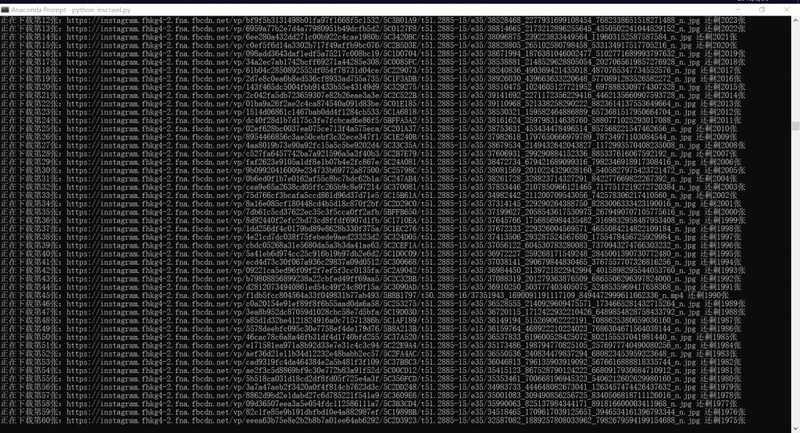
crawling_start
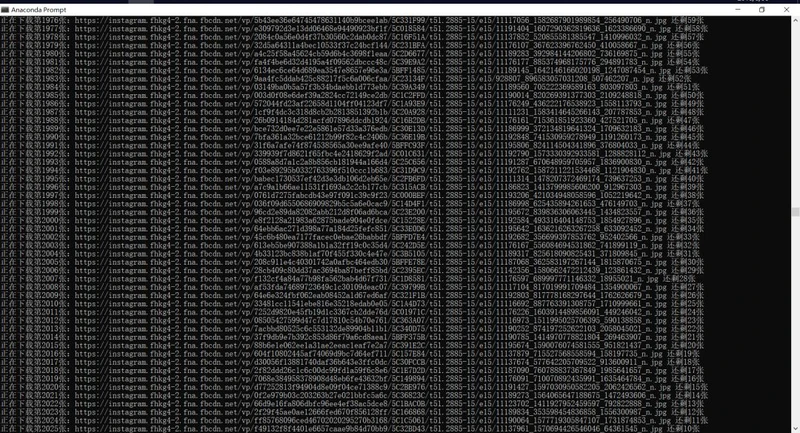
crwaling_end
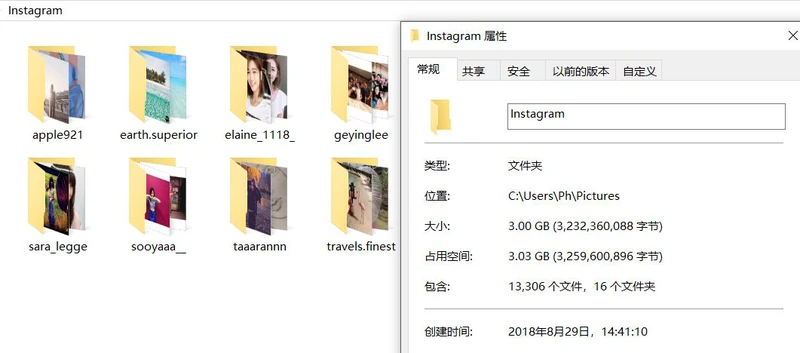
部分博主

图片示例
hashlibmd5
该部分代码如下:
display_urlvideo_urljpgmp4
最后的小问题
1. 429状态码
json429
响应状态码429 Too Many Requests
经过测试,2000条以内不会返回429,若爬取的博主有2000条以上帖子可以在请求json的时候加一点延迟,如上图代码块中的第96行。
2. 视频文件
XHRahref
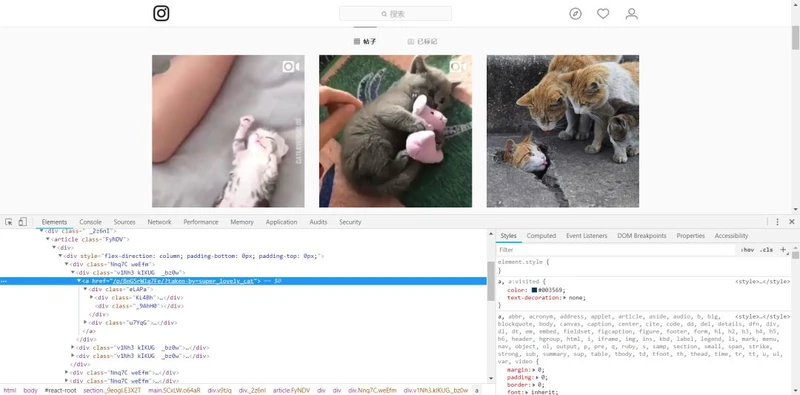
video_url
所以,博主前12条帖子里如果有视频则只能拿到一张展示图片。其次,类似的问题还有如果博主发的是超过1张的照片组,也只能拿到其中的第一张照片。
3. 下载方式
urlsurls
4. 爬虫效率
这里没有使用爬虫框架,也没有使用多线程。因为该爬虫只是出于学习交流的目的而写。
后记
以上就是所有的Instagram爬虫的爬虫逻辑和部分代码。初学不久,如有相关术语使用错误欢迎评论或私信指正。如有其它错误也欢迎评论或私信指正,如有上述小问题的解决方法或其它问题欢迎私信交流,最后,欢迎评论推荐Ins博主 (๑>◡<๑)
完整代码详见链接: https://github.com/linqingmaoer/Instagram_crawler

